What I just built
I just finished my first RAG solution. RAG, as in Retrieval-Augmented Generation. I know the rabbit hole goes deep with this stuff, but getting the first version working? Way smoother than I expected. Some of the ideas behind it genuinely caught me off guard.
The problem with keyword search
Regular search is keyword-based. You type “ruby” and it scans for the exact word “ruby.” If that string isn’t in the document, you get nothing.
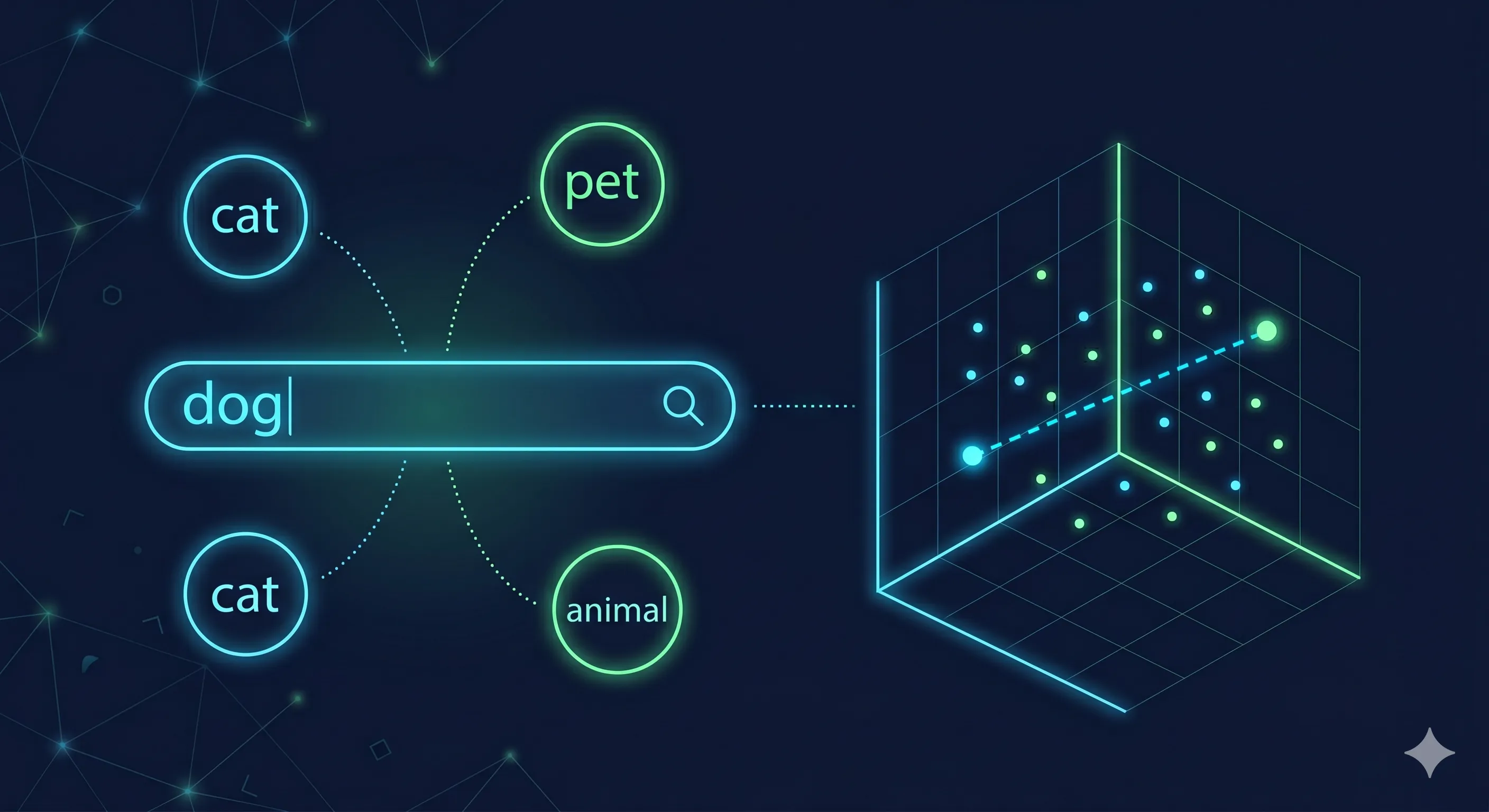
Semantic search is different. You search “ruby” and it might return stuff about “red,” because ruby and red are conceptually close. You search “dog” and there’s no dog in your database, but it gives you “cat,” because both are animals and the meaning overlaps.
You’re matching meaning, not words. That’s the whole shift.
Why this matters for chatbots
This gives chatbots a serious upgrade. Without RAG, a chatbot answers from whatever it picked up during training. That knowledge is broad, it’s frozen in time, and it’s not always right. The model might confidently give you garbage, or worse, say “I don’t know” when the answer is sitting right there in your data.
With RAG, the model first pulls relevant context from a knowledge base you control. Then it answers from that context. Two things happen: the model can look through way more information than its context window allows, and you can actually cite sources. You know where the answer came from. Not just “the AI said so.”
The part that got me: embeddings
This is where I got interested. Before this project, I had no idea what embedding models were. Now I keep thinking about them.
Imagine a graph. X-axis is how tall you are. Y-axis is how old you are. Plot any person as a single point. That point already tells you something real.
Now keep going. Add another axis for how funny they are. Another for how much they earn. Another for how much they like spicy food. Keep adding until you have thousands of axes. Each person still lands at one specific point in this massive space. That point says a lot about who they are.
That’s what an embedding model does with text. It turns a piece of text into a list of numbers. Think of them as coordinates. Texts with similar meaning end up near each other in that space.
So when someone asks a question, you embed the question the same way, then look for the closest stored points. The distance tells you how similar the meanings are. You don’t need to parse or understand the content during the search itself. The embedding already handled that part.
How it actually works
The basic flow:
- Break your documents into chunks
- Embed each chunk
- Store those embeddings in a vector database
- When a user asks something, embed their question too
- Compare the question’s embedding to all the stored ones
- Pull the closest matches and hand them to the AI as context
- The AI generates an answer from that retrieved information
The part I really like: you only embed your documents once. After that, the embeddings just sit in the vector database. No reprocessing unless your data changes.
Where I’m at
I expanded a lot of what I know about knowledge retrieval from this project. Embeddings, vector databases, how semantic similarity actually works. These ideas clicked in a way that reading articles about them never managed.
I’m still early in this space. But I understand enough now to see why everyone’s building with RAG. You get answers grounded in your own data, with sources you can trace back. That’s a big deal compared to trusting whatever the model picked up during training.
Before this project, “embedding” was just a word I’d skimmed past in AI blog posts. Now it’s the thing I keep coming back to. Usually a good sign.